Deploy the NVIDIA GPU Operator on CCE
The NVIDIA GPU Operator is a critical tool for effectively managing GPU resources in Kubernetes clusters. It serves as an abstraction layer over Kubernetes APIs, automating tasks such as dynamic provisioning, driver updates, resource allocation, and optimization for GPU-intensive workloads, thereby simplifying the deployment and management of GPU-accelerated applications. Its functionality extends to dynamic provisioning of GPUs on demand, managing driver updates, optimizing resource allocation for varied workloads, and integrating with monitoring tools for comprehensive insights into GPU usage and health. This guide outlines how to deploy the NVIDIA GPU Operator on CCE cluster. The process involves preparing GPU nodes, installing necessary components, configuring the cluster for GPU support, deploying an application leveraging GPUs, and verifying functionality.
Prerequisites
This blueprint requires:
- Access to the CCE cluster with kubectl.
- Helm installed on your system.
Preparing & Configuring a GPU Node Pool
Go to the Open Telekom Cloud console and choose the specific cluster you want to add the GPU node pool to. At the left sidebar select Nodes and click Create Node Pool.
Node Pool Configuration
Use the following values to configure the newly created GPU Node Pool:
- Name: Assign a meaningful name to your GPU node pool, such as
gpu-workers. - Flavor Selection: Choose a flavor that includes GPU resources. Look for options like
pi2.2xlargeor similar GPU-accelerated instances available. - Annotations: If required by your cluster's configuration, add any necessary annotations.
- Taints or Tolerations: Set taints or tolerations to manage pod scheduling. For GPU nodes, you might set a taint like
nvidia.com/gpu=true:NoExecuteand ensure pods requiring GPUs have the appropriate toleration.
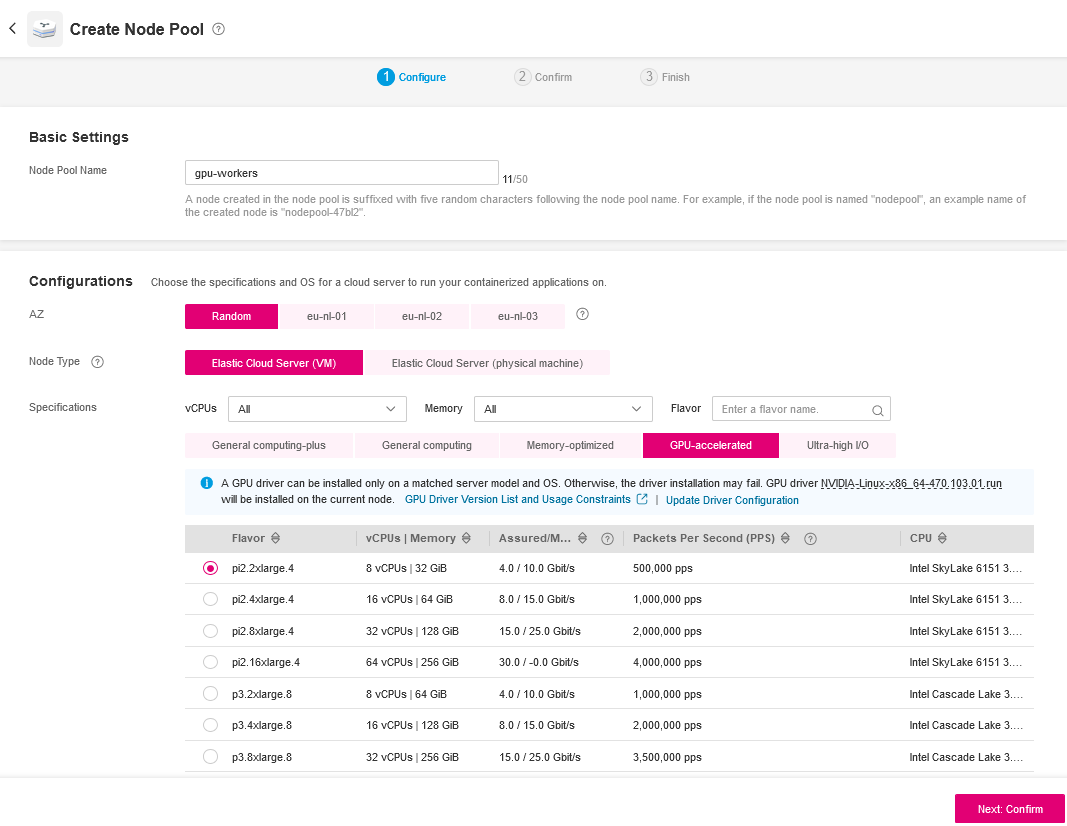
After creating the Node Pool scale it to the desired size.
Verification
Wait for some minutes until the nodes get provisioned and check if they have successfully joined the cluster with the following command:
kubectl get nodes --show-labels | grep "nvidia"
New GPU nodes should contain a label with accelerator as key and nvidia* as value (e.g. accelerator=nvidia-t4).
Installing the NVIDIA GPU Plugin
Installation
From sidebar select Add-ons and install the CCE AI Suite (NVIDIA GPU).
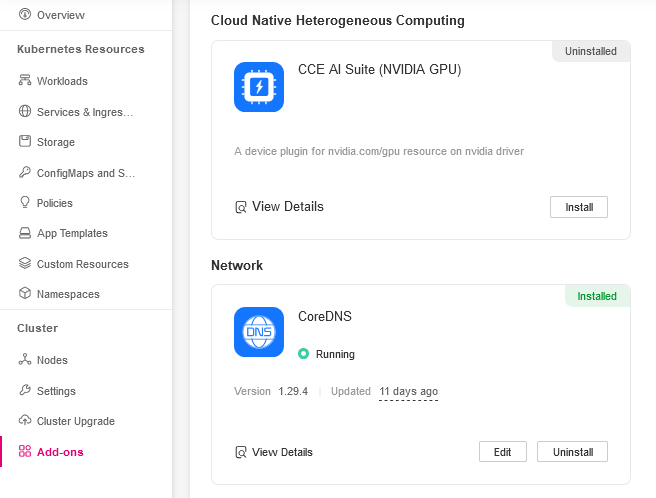
Plugin Configuration
For more information see CCE AI Suite (NVIDIA GPU).
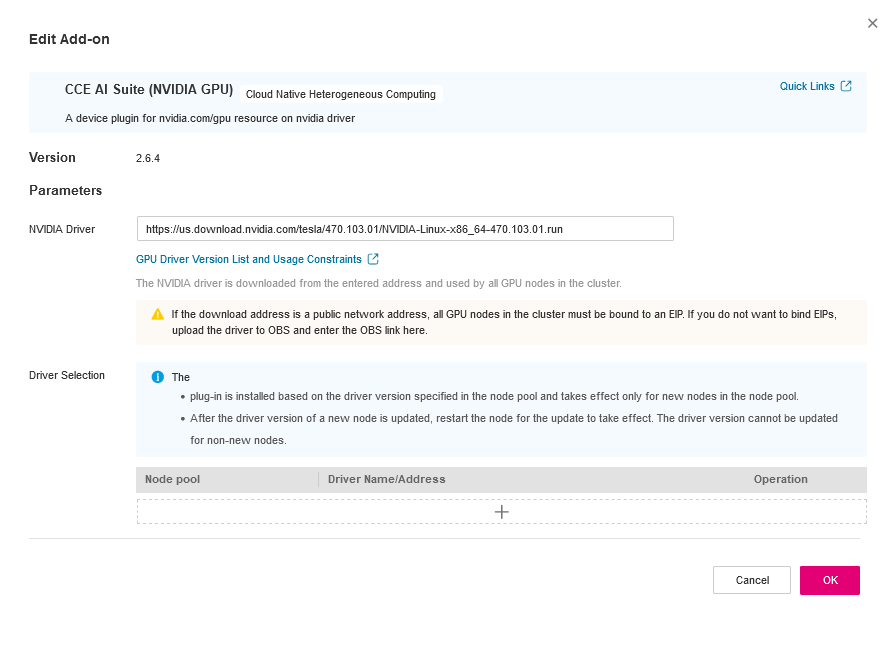
The selected driver must be compatible with the GPU nodes and supported by NVIDIA GPU Operator, otherwise the cluster will not be able to allocate GPU resources. Check supported drivers at:
Deploying the NVIDIA GPU Operator via Helm
Create a values.yaml file to include the required Helm Chart configuration values:
hostPaths:
driverInstallDir: "/usr/local/nvidia/"
driver:
enabled: false
toolkit:
enabled: false
hostPaths.driverInstallDir: The driver installation directory on CCE is different. Do not change this value!driver.enabled: Driver installation is disabled because it's already installed via CCE AI Suite.toolkit.enabled: The container toolkit installation is disabled because it's already installed via CCE AI Suite.
Now deploy the operator via helm:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install --wait gpu-operator \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
-f values.yaml \
--version=v24.9.2
Deploying an application with GPU Support
- Create a Pod Manifest: For example, deploying a CUDA job.
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1
- Apply the Manifest:
kubectl apply -f cuda-example.yaml
Validation
- Check Pod Status: Ensure pods are running.
kubectl get pods -n default
- Verify Logs: Check logs for GPU activity.
kubectl logs -f cuda-example-<pod-name> -n default
The containers' logs should indicate that the operation was succesfull, e.g.:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
Troubleshooting Tips
- Verify NVIDIA drivers are installed on nodes.
- Check resource requests and limits against cluster capacity.